New/s/leak: Struktur in unstrukturierten Daten sichtbar machen
Bei großen Daten-Leaks herausfinden, was in den Dokumenten Interessantes enthalten sein könnte, erfordert Zeit, die man eigentlich nicht hat — schließlich will jede Redaktion die erste sein. Algorithmen können Journalisten hier einen Teil der Vorrecherche abnehmen: Das Tool new/s/leak identifiziert Namen von Personen, Organisationen und Orten — und zeigt, wie sie zusammenhängen.
Die Panama-Papers waren das datenjournalistische Ereignis 2016 und haben zumindest in Deutschland die journalistische Arbeit mit großen Textmengen in ein neues Licht gerückt. Auch Beispiele wie Wikileaks oder die Snowden-Dokumentezeigen, wie wichtig es für Journalisten ist, computergestützt Informationen aus den Dokumenten zu ziehen, ohne erst jedes einzelne lesen zu müssen. Die Panama-Papers-Rechercheure, die international kollaborierten, brauchten Monate für ihre Arbeit.
Mit new/s/leak, dem Tool, das die Computerwissenschaftler Chris Biemann von der Universität Hamburg und Tatiana von Landesberger von der TU Darmstadt gemeinsam mit dem Journalisten Marcel Rosenbach, dem IT-Experten Stephan Heffner sowie der Computerlinguistin Michaela Regneri vom Magazin DER SPIEGEL konzipiert haben, wäre es vielleicht schneller gegangen, wichtige Personen und Organisationen in den Unterlagen zu identifizieren.
New/s/leak nimmt den Reportern das Durchkämmen von riesigen Dokumentensammlungen ein Stück weit ab, indem es Namen von Personen, Orten oder Organisationen hervorhebt und die Zusammenhänge zwischen ihnen in einem Netzwerk-Diagramm visualisiert.
Das erlaubt Nutzern, etwa Journalisten, die für ihre Recherchen relevanten Akteure schneller zu identifizieren und assoziierte Dokumente einfacher auszumachen. "Die Aufgeschlossenheit in der SPIEGEL-Redaktion gegenüber solcher Recherchemethoden ist sehr groß. Es gibt da auch einen enormen Bedarf, der mit jedem Daten-Leak wächst. Bei öffentlichen Leaks will jeder der erste sein, sodass Zeitdruck eine große Rolle spielt. In solchen Fällen ist man auf solche Tools angewiesen", sagt Regneri.
Daten bereinigen — aber nicht zu gründlich
Damit der Algorithmus überhaupt Namen identifizieren kann, werden die Daten zuerst vorklassifiziert: nach Metadaten und unstrukturiertem Textinhalt. Der Textinhalt wird dann bereinigt: "Bei der Bereinigung muss man aufpassen. Denn bei Texten ist es oft so, dass nicht die Worte interessant sind, die häufig auftauchen, sondern jene, die selten vorkommen. Journalisten interessieren sich besonders für die Stecknadel im Heuhaufen. Und wenn man zu viel bereinigen würde — wie es etwa für strukturierte Daten Standard ist — könnte es passieren, dass wir genau diese seltenen, interessanten Elemente wegfiltern", sagt Biemann.
"Manche Dokumente — etwa Telegramme aus dem Wikileaks PlusD Datensatz — sind komplett in Großbuchstaben verfasst. Für unsere Tools brauchen wir aber die übliche Groß- und Kleinschreibung, sodass die Texte erst einmal überarbeitet werden müssen. Einfach alles kleinzuschreiben wäre für unseren Zweck komplett destruktiv gewesen, weil wir ja versucht haben, Namensnetzwerke zu extrahieren. Und in englischen Texten ist Großschreibung ein gutes Signal, um Namen zu erkennen."
Nach der Bereinigung folgt die Namens-Analyse. Darauf ist der Algorithmus trainiert: Biemanns wissenschaftliche Hilfskräfte markierten manuell in 30.000 Sätzen jene Abschnitte, wo Personen, Orte, Organisationen oder andere Sorten von Namen genannt wurden. Der Algorithmus entwickelt darauf basierend selbst Regeln, um diese Namen zu erkennen. "Das, was zwischen 'former CEO' und 'said' steht, ist wahrscheinlich ein Name. Man kann das System entsprechend trainieren, solche Muster zu finden und dann auch neue Namen als solche zu erkennen, auch wenn der Algorithmus sie vorab noch nicht gesehen hat", sagt Biemann.
Algorithmen trainieren, eigenständig Namen zu identifizieren
Im Training ist das Modell noch dynamisch, der Algorithmus lernt immer neue Regeln und speichert, wie verlässlich sie funktionieren, um Namen zu identifizieren. "Am Ende des Trainingsprozesses kennt der Algorithmus viele solcher Regeln. Maschinelles Lernen funktioniert so, dass sich der Algorithmus aus einer Vielzahl möglicher Beobachtungen – "Features" genannt – diejenigen heraussucht, die für solche Regeln nützlich sind. Für jedes Feature merkt sich der Algorithmus, mit welchem Output — Personenname, Organisation oder Ort — es assoziiert ist. Und wenn ich das Modell dann auf neue Daten anwende, überprüft die Maschine die verschiedenen Features und entscheidet darauf basierend, ob es sich um einen Namen handelt oder nicht", erklärt Biemann.
Das Set an Regeln, das sich der Algorithmus auf Basis dieser Dokumente erarbeitet hat, ist erst einmal unveränderlich und dient dem Tool als Grundlage, um neue Daten zu verarbeiten.
Alle identifizierten Namen werden in einem Index abgelegt, der dann alle Dokumente und Metadaten listet, die mit diesem Namen assoziiert sind. Die grafische Oberfläche erlaubt dem Nutzer, das zu erkunden. Eine Verbindung in der new/s/leak-Visualisierung steht dabei für ein gemeinsames Vorkommen in Dokumenten — je mehr Dokumente beide Namen enthalten, desto stärker ist die Verbindung im Netzwerkdiagramm.
Trotz aller Trainings und Tests: Natürlich besteht die Möglichkeit, dass der Algorithmus Namen übersieht. "Wenn Dokumente eingescannt waren und bei der Optical Character Recognition (OCR) nicht richtig erkannt wurden oder im Zeilenumbruch hingen, dann kann es sein, dass das Tool das übersieht. Es weiß ja nicht, ob es schlecht eingescannt oder schlecht strukturiert war. So findet man dann bei der Volltextsuche vielleicht einen Begriff nicht, der eigentlich enthalten ist", sagt Biemann.
Auch bei den Namens-Netzwerken erkennt das Tool nicht alles. "Auch bei hochqualitativen Textsorten, wie Zeitungstexten oder Wikipedia, mit denen wir auch im Training arbeiten, erkennt es mindestens 8% der Personen, 20% der Firmen und 15% der Orte nicht richtig. Das muss man einfach hinnehmen. Deswegen ist uns auch sehr wichtig, dass das Tool einen Zugang zu den Originaldokumenten jedes Mal mitliefert. Ich würde mich nie hundertprozentig allein auf so ein Tool verlassen. Wenn der Journalist die Originalquellen konsultiert, findet er dann schon, was er braucht."
New/s/leak vereint Komponenten bisheriger Software in einem Tool
New/s/leak ist nicht das erste Tool, das Journalisten nutzen können, um Textmengen zu verarbeiten. Overview, Jigsaw (pdf) und Linkurious - letzteres kam unter anderem bei der Berichterstattung zu den Panama Papers zum Einsatz - verfolgen ebenfalls den Ansatz, Zusammenhänge in Texten zu erkennen und visuell darzustellen.
Jigsaw hat jedoch so viele Module, dass es am besten auf einer großen Bildschirmwand genutzt wird — oder alternativ auf mindestens vier normal großen Monitoren - eine Vorbedingung, die die meisten Journalisten nicht erfüllen können. Auch wenn die Demoversion von new/s/leak (empfohlener Browser: Chrome) aus vielen Elementen besteht, so passen sie zumindest auf einen einzigen Bildschirm. Im Vergleich zu Overview ist new/s/leak spezifischer: Overview sucht nicht gezielt nach Zeitpunkten, Personen, Orten und Organisationen. Ein ähnliches Tool, Documentcloud, macht dies zwar — jedoch ohne Netzwerkvisualisierung.
New/s/leak vereint alle diese Features in einem Tool — und kann nicht nur auf englische Texte, sondern auch auf deutsche Texte angewandt werden.
Auch das ist etwas besonderes, denn mit jeder zusätzlichen Sprache muss das Tool erneut angepasst werden. "Je mehr eine Sprache vom Englischen abweicht, umso höher ist der Anpassungs-Aufwand", sagt Biemann. "Arabische Worte und Sätze sind von rechts nach links geschrieben ist, was die Visualisierung schwieriger macht kann. Wie richtet man angesichts dessen Textelemente am besten aus? Bei Chinesisch ist die Herausforderung, dass Worte nicht durch Leerzeichen getrennt sind. Entsprechend müsste man hier noch eine Stufe Vorverarbeitung einfügen, um die Schriftzeichen in einzelne Wörter zu gliedern. Und erst dann eine Systematik entwickeln, um Namen zu erkennen." Auch für die deutsche Sprache mussten spezielle Module entwickelt werden, die dem Algorithmus helfen Grammatik und Worttypen zu erkennen — ein Teil der Forschungsarbeit von Biemanns Gruppe ist genau das.
Für die Konzeption eines solchen Werkzeugs wie new/s/leak ist jedoch nicht nur ein durchdachtes Back-End wichtig. Die Nutzeroberfläche ist mindestens ebenso relevant: "Eine gute Visualisierung sollte intuitiv verständlich sein", sagt Biemann. "Wir haben viel darüber diskutiert, was wir denn nun im Netzwerk zeigen: das Häufigste? Dann übersehen Sie vielleicht die spannenden Ausnahmen. Das Seltenste? Dann fehlt Ihnen der Gesamtzusammenhang." Deswegen war bei diesem Projekt auch eine Forschungsgruppe der TU Darmstadt involviert, die sich auf den Bereich Interaktionsgestaltung und Visualisierung fokussiert hat. "Derzeit wird das Tool noch nicht regelmäßig in die journalistische Arbeit mit eingebunden, kann aber bereits in einem gesicherten Umfeld produktiv genutzt werden.", so Heffner.
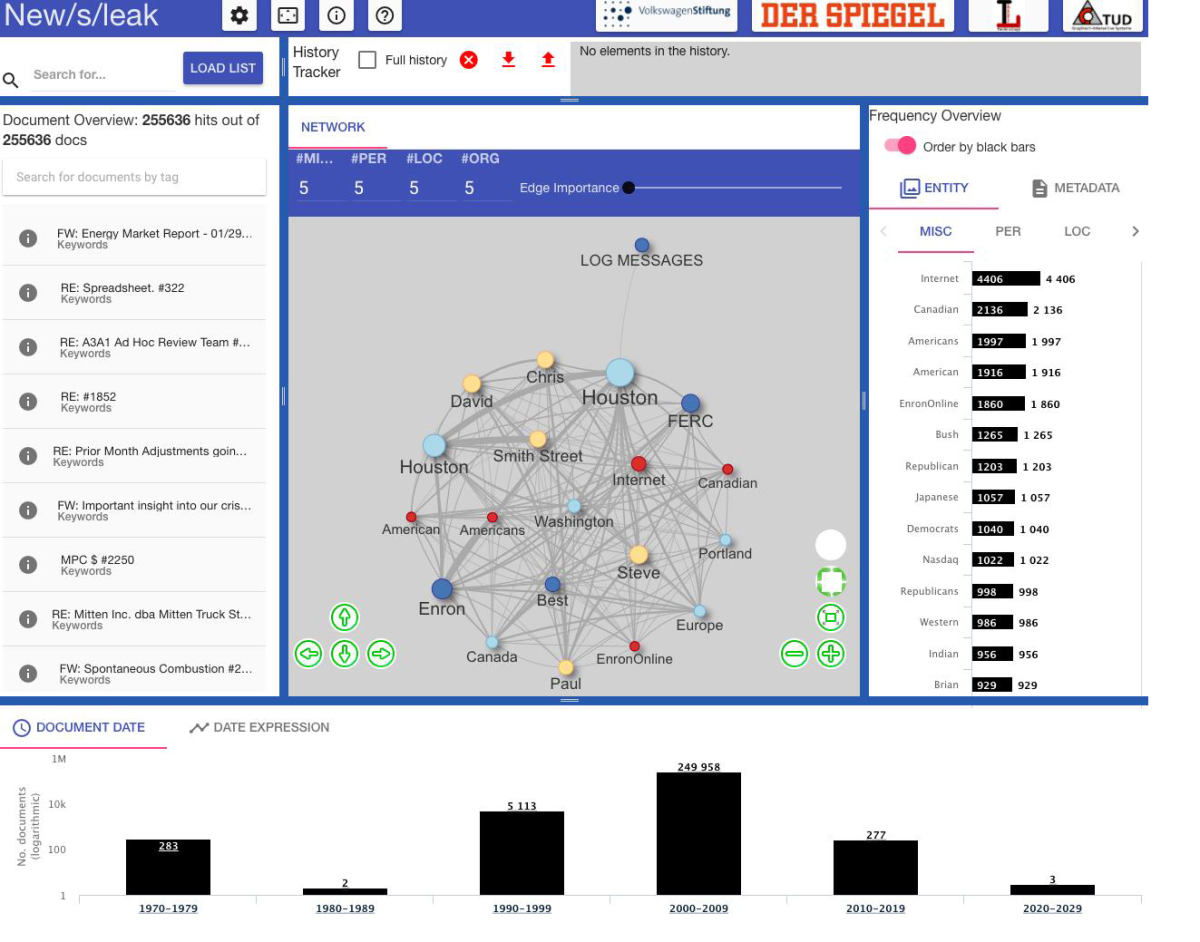
Demo-Version: Betrug bei Enron
Biemann und sein Team arbeiten derzeit daran, wie die Dokumente am nutzerfreundlichsten in das Tool gelangen, denn eine "Hochladen"-Funktion gibt es bislang noch nicht. Die Demo-Version zeigt aber schon alle anderen Werkzeuge, die die Endversion haben wird.

Im unteren Bildschirmbereich ist ein Datum-Histogramm, das anzeigt, für welchen Zeitraum es wie viele Dokumente gibt; über einen Klick auf einen der Balken lässt sich in den jeweiligen Zeitraum hineinzoomen.
Im rechten Bereich gibt es die Reiter "entity" und "metadata". Der Reiter "Metadata" zeigt, von wem wann eine E-Mail an wen geschickt wurde. "Die Zielfrage ist: Wer wusste wann was? Und das kann man hier erkunden", sagt Biemann.
Entity ist noch einmal unterteilt in PER (Personen), LOC (Orte) und ORG (Organisationen), der Reiter MISC (Verschiedenes). Alle Balken sind interaktiv und verändern auf Klick die Visualisierung in der Mitte. Das Netzwerkdiagramm im Mittelbereich lässt sich auch gezielt anpassen: so kann man die voreingestellte Anzahl der Namen von fünf hoch oder herunter setzen. Bei Klick auf einen der Punkte passen sich alle umliegenden Felder entsprechend an.
Bei so viel Anpassungsmöglichkeit ist der History-Tracker oben rechts besonders essentiell: Hier kann man nachvollziehen, welche Filter man ausgewählt hat und kann diese ggf. zurücksetzen — die eigene Suche lässt sich speichern und so auch mit Kollegen teilen.
Im linken Bereich gelangt man direkt zu den Dokumenten, auf denen die Visualisierung im Mittelbereich basiert. Der Nutzer kann hier eine Volltext-Suche durchführen oder auch Dokumente mit Labels versehen. "Anfangs dachten wir, dass in einer Email ausdrücklich drinsteht, 'Wir begehen jetzt Betrug' – aber das ist natürlich nicht so. Wir haben dann noch eine weitere Funktion eingebaut, über die man eine Liste von Suchbegriffen hineinladen kann, etwa Flüche wie 'Oh my god' also 'OMG', weil die Journalisten bemerkt haben, dass in den verdächtigen Emails häufiger geflucht wird als in gewöhnlichen", erzählt Biemann.
Die berühmte Nadel im Heuhaufen finden
Rückblickend hat sich während des Projektprozesses auch sein Anspruch geändert, was sein Team überhaupt leisten kann. "Wir hatten die Hoffnung, dass automatisch alles herauskommt, was interessant ist. Für die Journalisten war das meiste jedoch erst einmal nur indirekt interessant, als weiterer Recherche-Ansatz. Wir helfen also, die Nadel im Heuhaufen zu suchen und haben nicht (mehr) den Anspruch, dass wir auf Knopfdruck interessante Stories heraus generieren können."
Regneris Erwartungen haben sich eher nach oben angepasst: "Ich persönlich war gar nicht erst davon ausgegangen, dass die Software am Ende des Projektes schon produktiv nutzbar ist. Hauptsächlich erhoffte ich mir ein innovatives Ausgangsprodukt, das als Grundlage für Weiterentwicklungen dient. Außerdem wollten wir die Zusammenarbeit mit universitären Partnern im Haus etablieren. Da das Projekt im Verlauf immer besser wurde, haben sich natürlich auch die Erwartungen gesteigert - irgendwann war klar, dass wir das zu Projektende auch für 'echte' Daten-Leaks benutzen können und wollen", so Regneri.
"Für so ein Projekt werden die Ziele und Erfolgskriterien von allen beteiligten Seiten unterschiedlich wahrgenommen. Deswegen war der Fokus auf Anforderungs-Analyse und fundierte Feedback-Auswertung sehr wichtig. Je präziser hier die Anforderungen messbar sind, desto besser."
Ein Ziel für die Weiterarbeit an dem Projekt ist für Biemann, dem Nutzer noch mehr Einfluss auf das Tool zu geben und diesem beim Lernen zu helfen. "Das Tool macht ja nichts von selber, sondern braucht den Menschen und reagiert auf dessen Auswahl. Ich würde gerne eine Funktion einbauen, die es dem Tool erlaubt, vom Menschen zu lernen. Etwa wenn der Nutzer bei der Durchsicht der Dokumente noch einen Namen findet und den markieren kann, um der Maschine zu sagen: 'Ich möchte, dass du den kennst'. Das Schwierige ist, das statistische Modell dahinter zu ändern und das Tool daraus lernen zu lassen, neue Regeln abzuleiten und mehr von diesem Fall in dem Datensatz zu finden."
Gianna Grün
Projektinformationen New/s/leak
Hauptantragsteller:
Chris Biemann, Technische Universität Darmstadt
Tatiana von Landesberger, Technische Universität Darmstadt
Marcel Rosenbach, DER SPIEGEL
Website New/s/leak: http://newsleak.io
Demo-Version New/s/leak (empfohlener Browser: Chrome): http://ltbev.informatik.uni-hamburg.de/newsleak/#
Publikationen
Yimam, S.M., Ulrich, H., von Landesberger, T., Rosenbach, M., Regneri, M., Panchenko, A., Lehmann, F., Fahrer, U., Biemann, C. and Ballweg, K. (2016): new/s/leak – Information
Extraction and Visualization for an Investigative Data Journalists. ACL 2016 Demo Session, p. 163-168, Berlin, Germany.
http://aclweb.org/anthology/P/P16/P16-4028.pdf
Ballweg K., Zouhar F., Wilhelmi-Dworski P., von Landesberger T., Fahrer U., Panchenko A., Yimam S.M. Biemann C., Regneri M., Ulrich H. (2016) new/s/leak – A Tool for Visual Exploration of Large Text Document Collections in the Journalistic Domain, Workshop on Visualization in Practice as part of IEEE VIS Conference, Baltimore, MD, USA.
http://www.gris.tu-darmstadt.de/research/vissearch/publications/pdf/ballweg2016VIP.pdf
Lehmann, F. (2016) new/s/leak – Anforderungsanalyse einer interaktiven Visualisierung für Data-Driven Journalism. INFORMATIK 2016, LNI, Gesellschaft für Informatik, pp. 2113-2125, Klagenfurt, Austria.
http://subs.emis.de/LNI/Proceedings/Proceedings259/2113.pdf
Müller, M., Ballweg, K. von Landesberger, T., Yimam, S.M., Fahrer, U., Biemann, C., Rosenbach, M., Regneri, M., Ulrich, H. (2017). Guidance for Multi-Type Entity Graphs from Text Collections. EuroVis Workshop on Visual Analytics 2017, Barcelona, Spain. https://www.inf.uni-hamburg.de/en/inst/ab/lt/publications/2017-mueller-eurovanewsleak-guidance.pdf